Repitamos todo el proceso pero ejecutando el algoritmo k-Means considerando las 4 características del dataset Iris:
iris = sns.load_dataset("iris")
model = KMeans(n_clusters = 3, random_state = 0)
model.fit(iris.drop("species", axis = 1))

Añadimos como nueva columna las etiquetas obtenidas:
iris["cluster"] = model.predict(iris.drop("species", axis = 1))
Volvemos a mostrar la gráfica inicial y la correspondiente a la nueva predicción:
fig, ax = plt.subplots(2, 1, figsize = (6, 8))
sns.scatterplot("sepal_length", "sepal_width", data = iris, hue = "species", ax = ax[0]);
sns.scatterplot("sepal_length", "sepal_width", data = iris, hue = "cluster",
palette = "gist_stern", ax = ax[1]);
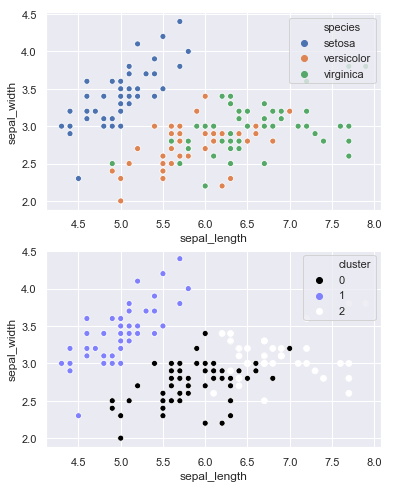
Ya visualmente se aprecia que los clusters creados se adaptan mucho mejor a los datos reales. Confirmémoslo calculando la matriz de confusión:
confusion_matrix(iris.species.map(d), iris.cluster)
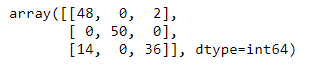
El número de muestras correctamente clasificadas ahora es bastante mayor. Calculemos el accuracy_score:
accuracy_score(iris.species.map(d), iris.cluster)
...bastante más elevado que en el primer análisis.