Probemos DBSCAN con el dataset lunas que tantos problemas supuso para k-Means: creamos las características x e y, y las mostramos en un diagrama de dispersión:
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=400, noise=0.05, random_state=0)
x = X[:, 0]
y = X[:, 1]
sns.scatterplot(x, y, legend = False);
Ahora importamos el algoritmo:
from sklearn.cluster import DBSCAN
Lo instanciamos indicando una distancia máxima entre puntos de 0.2:
model = DBSCAN(eps = 0.2)
Lo entrenamos y generamos la predicción:
clusters = model.fit_predict(X)
Ahora ya podemos repetir el gráfico mostrando cada cluster de un color diferente:
sns.scatterplot(x, y, hue = clusters);
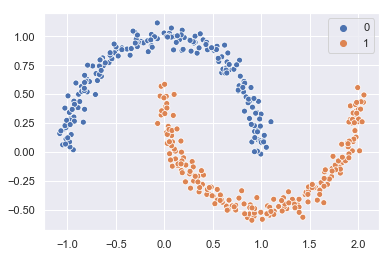
Confirmamos que la identificación de los clusters -según el criterio de densidad- ha sido perfecta.