La regresión logística es un tipo de análisis utilizado para predecir el resultado de una variable categórica en función de un conjunto de variables independientes. Puede obtenerse en seaborn añadiendo el argumento logistic = True a la función seaborn.lmplot (o a seaborn.regplot). Para que funcione, la variable a situar en el eje y deberá ser binaria, en cuyo caso seaborn usará statsmodels para la estimación del modelo.
Por ejemplo supongamos que deseamos saber la probabilidad de que el comensal que deja la propina sea un hombre en función del total de la cuenta. Comenzamos cargando el dataset tips y añadiendo una nueva característica binaria indicando si el comensal es o no hombre:
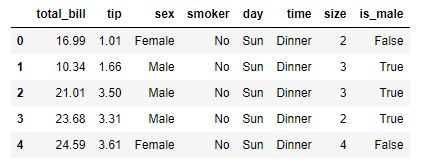
tips = sns.load_dataset("tips")
tips["is_male"] = tips["sex"] == "Male"
tips.head()
A continuación ejecutamos la función seaborn.lmplot mostrando en el eje y el campo creado, is_male, y añadiendo el argumento logistic = True:
sns.lmplot(x = "total_bill", y = "is_male", data = tips, logistic = True);
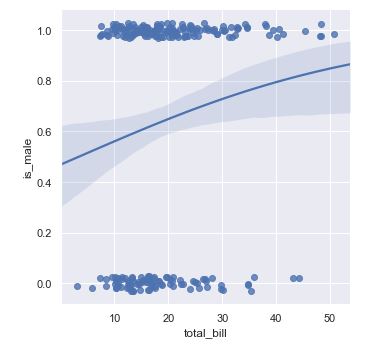
La función muestra la regresión logística buscada y el intervalo de confianza.
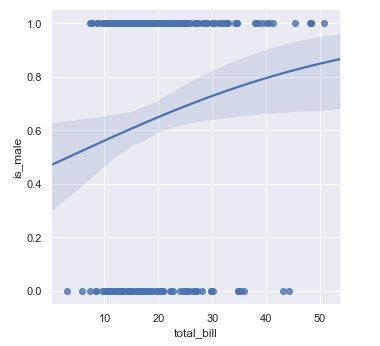
Vemos cómo se han representado los puntos correspondientes a los valores False y True (interpretados como 0 y 1, respectivamente), pero los puntos están tan próximos unos a otros que resulta difícil distinguirlos. Las funciones sns.lmplot y sns.regplot admiten dos parámetros que pueden ser de utilidad en casos como éste: x_jitter e y_jitter. El primero añade un cierto "temblor" horizontal a los puntos, y el segundo un cierto temblor vertical. Si repetimos la visualización anterior añadiendo el argumento y_jitter, el resultado es el siguiente:
sns.lmplot(x = "total_bill", y = "is_male", data = tips, logistic = True, y_jitter = 0.03);