Un caso especial de gráficos de líneas lo encontramos cuando para cada valor de x puede existir más de un valor y. En estos casos, el comportamiento por defecto de seaborn es mostrar el valor medio de los valores y el intervalo de confianza del 95%. Un ejemplo de este tipo lo encontramos en el dataset de ejemplo flights, con información del número de pasajeros transportados por mes y por año:
flights = sns.load_dataset("flights")
flights.sample(5)
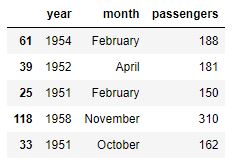
Mostremos la gráfica de líneas de pasajeros transportados por año:
sns.relplot(x = "year", y = "passengers", kind = "line", data = flights);
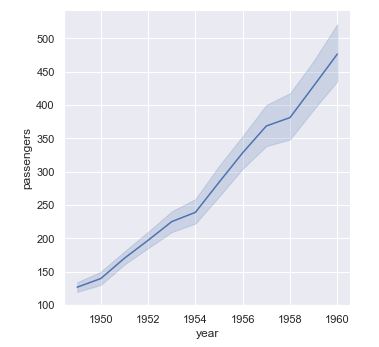
La línea principal mostrada de color azul oscuro es el valor medio de los pasajeros transportados el año correspondiente, y el área azul claro por encima y por debajo supone el intervalo de confianza del 95%. Este intervalo es calculado usando bootstrapping.
El parámetro ci (confidence interval) controla el comportamiento de esta opción. Puede tomar como valores un número, el texto "sd", False o None. En el primer caso indicará el intervalo de confianza a aplicar (habrá que indicar un número entero entre 0 y 100. El valor por defecto, como hemos visto, es 95). En el siguiente ejemplo se muestra la misma gráfica con un intervalo de confianza del 40%:
sns.relplot(x = "year", y = "passengers", kind = "line", data = flights, ci = 40);
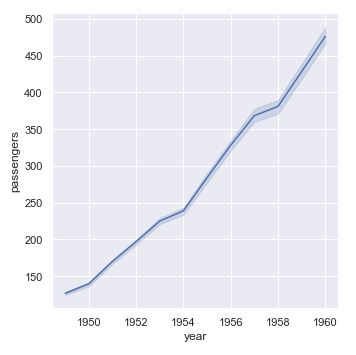
Si toma el valor "sd" se mostrará la desviación estándar de los datos:
sns.relplot(x = "year", y = "passengers", kind = "line", data = flights, ci = "sd");
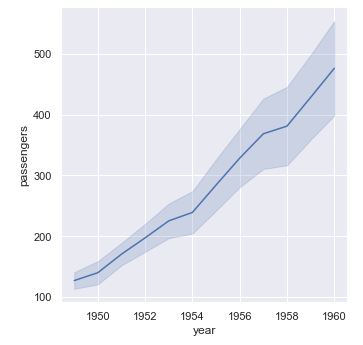
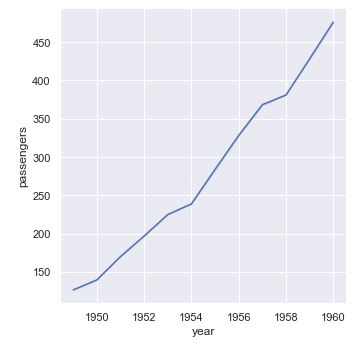
Por último, pasando al parámetro el valor None o False se desactiva el cálculo del intervalo de confianza:
sns.relplot(x = "year", y = "passengers", kind = "line", data = flights, ci = False);
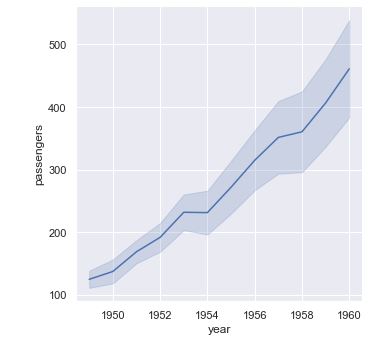
De hecho, todos los ejemplos anteriores han mostrado un intervalo de confianza en torno al valor medio de los datos, pero es posible agregarlos según otros métodos de pandas utilizando el parámetro estimator. Por ejemplo, según la mediana:
sns.relplot(x = "year", y = "passengers", kind = "line", data = flights, estimator = "median", ci = "sd");
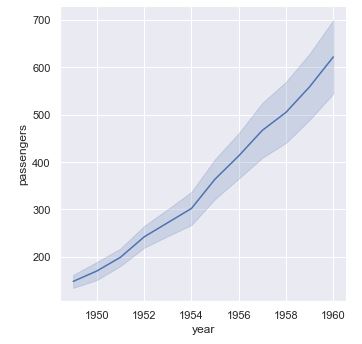
...según el valor máximo:
sns.relplot(x = "year", y = "passengers", kind = "line", data = flights, estimator = "max", ci = "sd");
...etc.
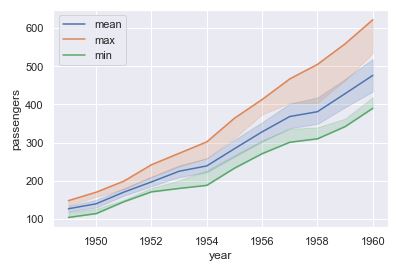
Usando la función a nivel de ejes equivalente, sns.lineplot, podemos mostrar la gráfica anterior con tres estimadores (correspondientes al valor medio, máximo y mínimo) y ver cómo se representa cada uno:
sns.lineplot(x = "year", y = "passengers", data = flights, estimator = "mean", label = "mean");
sns.lineplot(x = "year", y = "passengers", data = flights, estimator = "max", label = "max");
sns.lineplot(x = "year", y = "passengers", data = flights, estimator = "min", label = "min");