Cluster Map muestra información -supuestamente agrupada en clusters según algún criterio- en forma de nube de imágenes. Su configuración es la mostrada en la siguiente imagen:
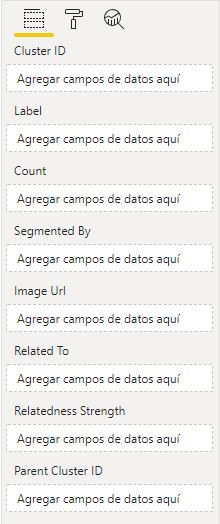
Los únicos campos obligatorios son los tres primeros: Cluster ID (identificador de los elementos a mostrar, no de los supuestos clusters -salvo que en esta visualización se denomine cluster a cada uno de los elementos-), Label (etiqueta de cada uno de los elementos a mostrar) y Count (métrica que va a asociarse a los elementos y que va a determinar su ordenación en la visualización).
Supongamos que queremos mostrar los mejores vendedores de nuestra empresa: Arrastremos el campo Employee Id de nuestra tabla de vendedores al campo Cluster ID, el campo Full Name (nombre del vendedor) al campo Label, y la medida Sales (suma de la cifra de ventas en el contexto actual) a Count. La visualización mostrará el siguiente aspecto:
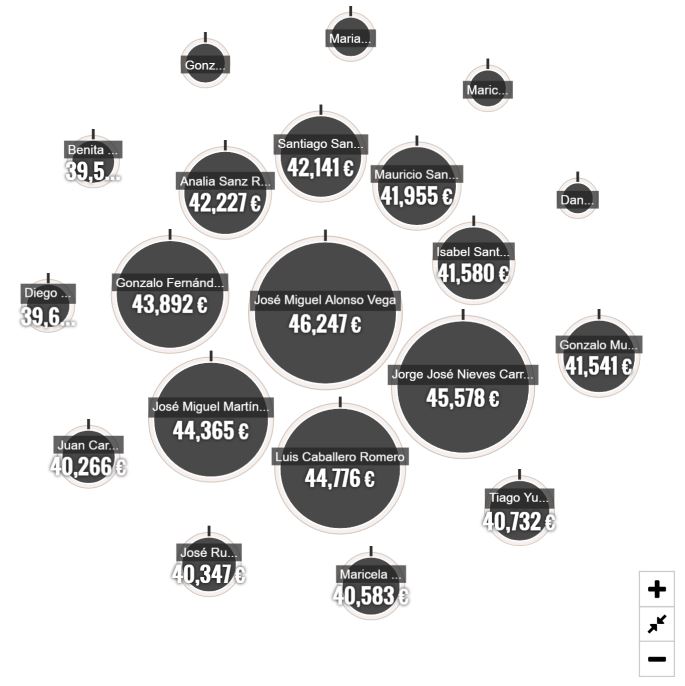
Como puede verse, los vendedores con mayor cifra de ventas se representan con círculos de mayor tamaño, permitiendo fácilmente identificar a los mejores. Por otro lado, ni los tamaños ni los radios de los círculos son proporcionales a la cifra en cuestión, lo que puede dificultar su interpretación (afortunadamente se muestra la cifra en el medio del círculo).
Si llevamos al campo Image Url de la visualización el campo Picture de nuestra tabla de vendedores -campo que contiene los URLs con las fotografías de éstos- la visualización se actualizará para mostrar las imágenes en cada círculo:

Vemos en estas últimas dos imágenes un inconveniente adicional de esta visualización: las etiquetas no se muestran correctamente salvo para aquellos elementos con un valor asociado alto (es decir, para elementos con un círculo de suficiente diámetro). Y mover el cursor encima de uno de los elementos no provoca la aparición de la típica ventana flotante con la información asociada, de forma que nunca sabremos ese "Dani..." que se muestra cerca de la esquina superior derecha de la anterior imagen a qué vendedor se refiere (salvo que solo haya un Daniel, por supuesto). Además, para estos elementos con cifras asociadas pequeñas, la imagen resulta prácticamente invisible, lo que no ayuda en la identificación del elemento en cuestión.
El campo Segmented By se supone que sirve para agrupar los elementos en clusters (o, al menos, para segmentar de alguna forma los elementos), pero el cambio que produce su uso en la visualización es prácticamente imposible de interpretar. Por ejemplo, si llevamos el campo Country de nuestro modelo de datos con el fin de identificar a qué país pertenece cada vendedor, el resultado es el siguiente:

La imagen puede parecer idéntica a la anterior pero, si nos fijamos, vemos que ha aparecido un borde en torno a los círculos que se supone que debería permitirnos distinguir los elementos de un país de los de otro (pero no lo permite demasiado bien, para qué decir otra cosa). Si los colores escogidos para cada segmento fuesen personalizables, todavía... pero no lo son.
Los otros tres campos, Related To, Relatedness Strength y Parent Cluster ID sirven -aparentemente, pues no hay documentación a la que recurrir- para asociar los elementos a otros a los que estén relacionados. Por ejemplo, nuestra tabla de vendedores incluye un campo ("Manager") con el identificador del supervisor de cada vendedor (en el modelo de datos que estamos usando no todos los trabajadores tienen un supervisor). Si llevamos este campo al campo Related To de la visualización, los vendedores que tienen un supervisor en el grupo de mejores vendedores se muestran unidos a éstos:

En la imagen anterior, los grupos de vendedor-supervisor se muestran en el lateral izquierdo y en la parte superior de la visualización.
Los otros dos campos (Relatedness Strength y Parent Cluster ID) no tienen una utilidad fácilmente interpretable.
Un clic en uno de los elementos lo destaca frente al resto y filtra el resto de visualizaciones del informe.
La visualización es muy poco configurable: apenas los colores a mostrar alrededor de un círculo cuando se selecciona, si mostrar las etiquetas o no, si los círculos deberán mostrarse en espiral o en modo "relacional" (qué elementos se relacionan con qué otros) y poco más.
Como resumen, haría falta documentación, mayor capacidad de personalización y resolver los problemas de usabilidad comentados para poder considerar esta visualización verdaderamente útil.