class sklearn.impute.SimpleImputer(missing_values=nan, strategy=’mean’, fill_value=None, verbose=0, copy=True)
La función sklearn.impute.SimpleImputer permite sustituir valores nulos por otros valores según varias estrategias disponibles. La estrategia a ejecutar se indica mediante el parámetro strategy.
Una vez instanciado el imputador, puede entrenarse con el método fit (que genera un array conteniendo los valores por los que sustituir los valores nulos de cada característica) y puede ejecutarse la sustitución con el método transform. El atributo statistics_ nos da acceso al array de valores a imputar (uno por cada característica). Debe tenerse en cuenta que el resultado del imputador es un array NumPy, no un dataframe.
- missing_values: Objeto que representa un valor nulo. Puede ser un número, una cadena de texto, np.ana (valor por defecto) o None.
- strategy: Estrategia a ejecutar. Puede tomar los siguientes valores
- mean: (opción por defecto) reemplazando los valores nulos con la media de los valores de su misma columna
- median: reemplazando los valores nulos con la mediana de los valores de su misma columna
- most_frequent: reemplazando los valores nulos con el valor más frecuente de su misma columna
- constant: reemplazando los valores nulos con un valor constante, pudiendo ser tanto un número como una cadena de texto
En este último caso, el parámetro fill_value indica el valor en cuestión.
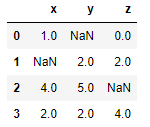
Partimos del siguiente dataframe:
df = pd.DataFrame({
"x": [1, np.nan, 4, 2],
"y": [np.nan, 2, 5, 2],
"z": [0, 2, np.nan, 4]
})
df
Importamos e instanciamos ahora el imputador:
from sklearn.impute import SimpleImputer
si = SimpleImputer()
Lo entrenamos (ya hemos visto que, por defecto, la estrategia es el sustituir los valores nulos por el valor medio de las características):
si.fit(df)
Los valores a imputar ya han sido calculados:
si.statistics_
Por último, podríamos generar el array final usando el método transform:
si.transform(df)
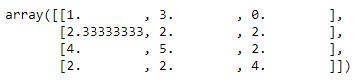
También podríamos haber modificado los datos originales directamente usando el método fit_transform:
si.fit_transform(df)

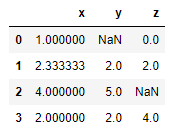
Podríamos sustituir los valores nulos tan solo de una de las características aplicando el imputador solo a la columna correspondiente, considerando que los métodos de entrenamiento de esta función esperan un array de entrada de dos dimensiones:
df["x"] = si.fit_transform(df["x"].values.reshape(-1, 1))
df
(en un caso sencillo como éste también podríamos recurrir a la función fillna de pandas).