sklearn.preprocessing.MaxAbsScaler(copy=True)
La función sklearn.preprocessing.MaxAbsScaler escala y traslada cada característica del array de entrada de forma que el valor absoluto máximo de cada una sea 1.0 (es decir, todas las características pasan a tener valores en el rango [-1, 1]).
El array de entrada debe ser de números reales (enteros o de tipo float). No se aceptan números complejos.
- copy: (True por defecto) booleano. Si toma el valor False y el array de entrada es un array NumPy, la transformación se realiza inplace.
Atributos:
- scale_: (array) escalado relativo de cada característica
- max_abs_: (array) máximo valor de cada característica
- n_samples_seen_: (entero), número de muestras (filas) procesadas.
El resultado de los métodos fit_transform y transform es siempre un array NumPy de tipo float.
Comenzamos importando las librerías involucradas y creando el dataframe que queremos escalar:
import pandas as pd
import numpy as np
from sklearn.preprocessing import MaxAbsScaler
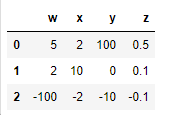
df = pd.DataFrame({
"w": [5, 2, -100],
"x": [2, 10, -2],
"y": [100, 0, -10],
"z": [0.5, 0.1, -0.1],
})
df
Instanciamos el escalador, lo entrenamos con el dataframe y lo transformamos:
scaler = MaxAbsScaler()
scaler.fit_transform(df)

Observamos que los valores máximos y mínimos en todas las características son 1 y -1. El procedimiento seguido por el escalador ha sido comprobar el valor máximo absoluto de cada característica y dividir todas los valores (de cada característica) por su máximo absoluto. Podemos comprobar los valores máximos encontrados visualizando el valor del atributo max_abs_:
scaler.max_abs_
La escala aplicada (cifra por la que dividir los valores de cada característica) viene dada por el atributo scale_ (la escala debe coincidir con el valor máximo encontrado):
scaler.scale_
Por último, el atributo n_samples_seen_ devuelve el número de muestras (filas de datos) procesadas:
scaler.n_samples_seen_
3
¿Y cómo se gestionan los valores nulos? Hagamos la prueba:
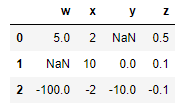
df = pd.DataFrame({
"w": [5, np.nan, -100],
"x": [2, 10, -2],
"y": [np.nan, 0, -10],
"z": [0.5, 0.1, -0.1],
})
df
scaler.fit_transform(df)
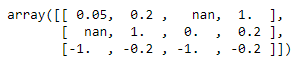
Veamos los valores máximos encontrados:
scaler.max_abs_
Comprobamos que los valores nulos se ignoran durante el entrenamiento y se mantienen durante la transformación.
¿Y si todos los valores de una característica son nulos?
df = pd.DataFrame({
"w": [5, np.nan, -100],
"x": [2, 10, -2],
"y": [np.nan, np.nan, np.nan],
"z": [0.5, 0.1, -0.1],
})
df
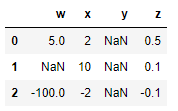
scaler.fit_transform(df)

Vemos que, a pesar del error que devuelve, el resultado es correcto.