DataFrame.drop(
labels = None,
axis = 0,
index = None,
columns = None,
level = None,
inplace = False,
errors = 'raise'
)
El método .drop() asociado a un dataframe pandas devuelve una copia del mismo tras eliminar las filas o columnas indicadas. Éstas deberán referenciarse por sus etiquetas explícitas, no por su posición en el eje.
La eliminación se realiza, por defecto, en el eje vertical (se eliminan filas, por lo tanto).
- labels: Etiqueta o lista de etiquetas a eliminar.
- axis: Eje en el que realizar la eliminación. Puede indicarse el valor 0 o "index" para hacer referencia al eje 0 (y eliminar filas), o el valor 1 o "columns" para hacer referencia al eje 1 (y eliminar columnas). El valor por defecto es 0.
- index: Etiqueta o lista de etiquetas a eliminar del eje 0.
- columns: Etiqueta o lista de etiquetas a eliminar del eje 1.
- level: Número entero o nombre del nivel a eliminar de un índice multinivel.
- inplace: Booleano. Si toma el valor True, la eliminación se realiza en el mismo dataframe. Si toma el valor False, el método devuelve una copia del dataframe tras eliminar las filas o columnas especificadas.
- errors: Este parámetro puede tomar los valores "ignore" o "raise" y se considera cuando alguna de las etiquetas referenciadas no existe. El valor por defecto es "raise" lo que provoca que la función devuelva un error cuando alguna etiqueta no exista. Si se fija el valor de este parámetro a "ignore", los errores son ignorados.
Los parámetros index y columns son alternativas al parámetro axis. Solo puede indicarse un parámetro de entre axis, index y columns.
El resultado es un dataframe pandas con independencia del número de filas o columnas que se eliminen.
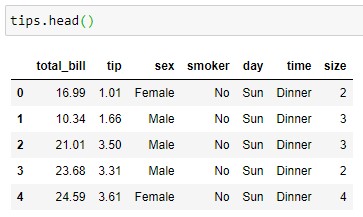
Partimos del dataframe tips proveído por seaborn:
tips.head()
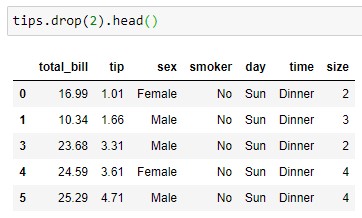
Por defecto se eliminan filas y se devuelve una copia del dataframe tras realizar la eliminación:
tips.drop(2).head()
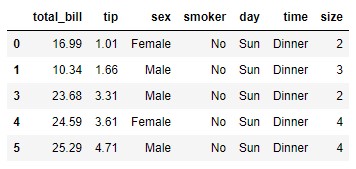
Obtenemos el mismo resultado si especificamos el parámetro "index":
tips.drop(index = 2).head()
Es posible eliminar simultáneamente más de una fila o columna pasando como argumento no una etiqueta sino una lista de ellas:
tips.drop(columns = ["tip", "smoker"]).head()

Si alguna de las etiquetas indicadas no existe, el método devuelve un error:
try:
tips.drop(columns = ["tip", "smoker", "weather"]).head()
except:
print("Error")
Error
Sin embargo, podemos forzar que la función ignore estas etiquetas inexistentes asignando al parámetro errors el valor "ignore":
tips.drop(columns = ["tip", "smoker", "weather"], errors = "ignore").head()

El resultado es un dataframe aun cuando se eliminen todas las filas o todas las columnas:
df = tips.drop(tips.columns, axis = 1)
df

type(df)
pandas.core.frame.DataFrame
Multi-índices
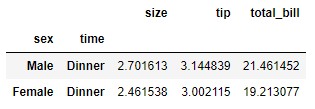
Para probar el comportamiento de esta función con multi-índices partimos del siguiente dataframe:
data = tips.pivot_table(index = ["sex", "time"])
data
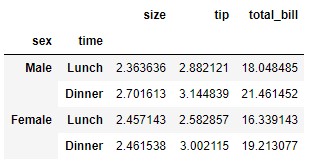
Si deseamos eliminar, por ejemplo, la etiqueta "Male" del índice (etiqueta que se encuentra en el nivel 0 del multi-índice), podemos conseguirlo con el siguiente código:
data.drop(index = ["Male"], level = 0)
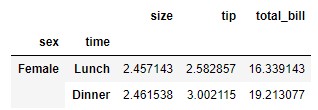
Podemos obtener el mismo resultado haciendo referencia no al nivel, sino a su nombre:
data.drop(index = ["Male"], level = "sex")
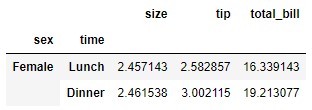
La función permite eliminar etiquetas de niveles "superiores". Por ejemplo:
data.drop(index = ["Lunch"], level = "time")