La función GROUPBY es similar a la función SUMMARIZE pero solo admite funciones iterativas (SUMX, MINX, etc.) ya que no se ejecuta un CALCULATE implícito sobre las expresiones. Los grupos formados no son afectados por el contexto de filtro.
GROUPBY(
table,
groupBy_columnName
[, groupBy_columnName]…
[, name,
expression]…
)
- table: Referencia a una tabla, o expresión DAX que devuelve una tabla.
- groupBy_columnName: Nombre totalmente cualificado de una columna existente en la tabla anterior o en alguna tabla relacionada para crear los grupos basados en los valores que se encuentren en ella. No puede ser una expresión.
- name: Nombre dado al total calculado en expression.
- expression: Expresión DAX que devuelve un escalar que será utilizada para el cálculo de los totales. Esta expresión deberá ser de tipo iterativo e incluirá la función CURRENTGROUP como primer argumento.
La función GROUPBY devuelve una tabla teniendo como columnas las especificadas en el argumento groupBy_columnName (valores que van a especificar los criterios de agregación) y las añadidas como name que contendrán el resultado de evaluar expression para las combinaciones de los campos groupBy_columnName.
Cada columna que añadamos como name deberá ir acompañada de la expresión que la define. En cualquier otro caso la función devolverá un error.
Los campos groupBy_columnName deberán pertenecer o bien a la tabla indicada en el primer argumento, o bien a una tabla relacionada con ella.
Los nombres añadidos como name deberán ir encerrados entre comillas dobles.
El número de filas de la tabla vendrá determinado por el número de valores distintos que tomen los campos groupBy_columnName. Si solo se incluye un campo que toma 4 valores distintos, el resultado será una tabla con 4 filas. Si se incluyen dos valores que toman, respectivamente, 3 y 4 valores distintos, el resultado será una tabla con 4 x 3 = 12 filas (una para cada combinación de los valores de ambos campos).
La función GROUPBY se ejecuta de la siguiente forma:
- Comienza con la tabla especificada y las tablas relacionadas implicadas.
- Crea grupos basados en los valores contenidos en los argumentos groupBy_columnName.
- Para cada grupo, evalúa las expresiones indicadas, pero, al contrario de lo que ocurre con la función SUMMARIZE, no se ejecuta un CALCULATE implícito, no considerándose, por lo tanto, el contexto de filtro.
La función GROUPBY puede ser más lenta que las funciones SUMMARIZE o SUMMARIZECOLUMNS. Sin embargo, el hecho de calcular las expresiones en un contexto de fila permite abordar ciertos escenarios que las mencionadas funciones no permiten.
Dentro de la función iterativa deberá usarse la función CURRENTGROUP como primer argumento.
Partimos en este ejemplo de una tabla de ventas, Sales, y de campos en tablas remotas relacionadas que contienen el nombre del país en el que se produce la venta (Geography[Country]), y el sexo del comprador (Customer[Gender]). El objetivo es crear una tabla que muestre las ventas por país y sexo del comprador. El código sería el siguiente:
Sales per country and gender =
GROUPBY(
Sales,
Geography[Country],
Customer[Gender],
"Total sales", SUMX(CURRENTGROUP(), SUM(Sales[SalesAmount]))
)
Puede observarse el uso de la función CURRENTGROUP como primer argumento de la función iterativa SUMX.
Si llevamos los campos resultantes a una tabla, el resultado es el siguiente:
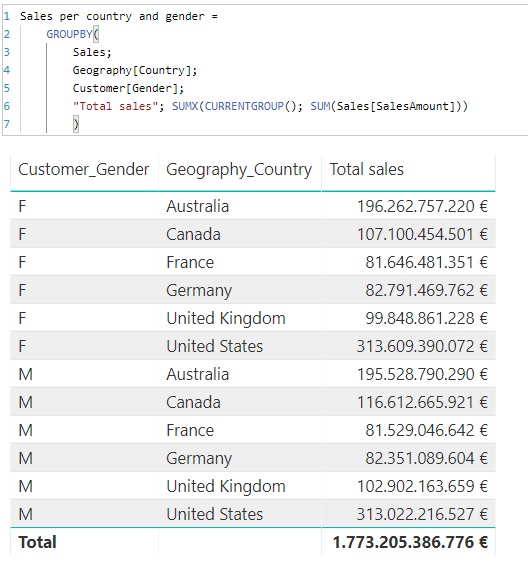
Siguiendo con el mismo ejemplo, podemos añadir una segmentación de datos con el listado de países y seleccionar uno de ellos:
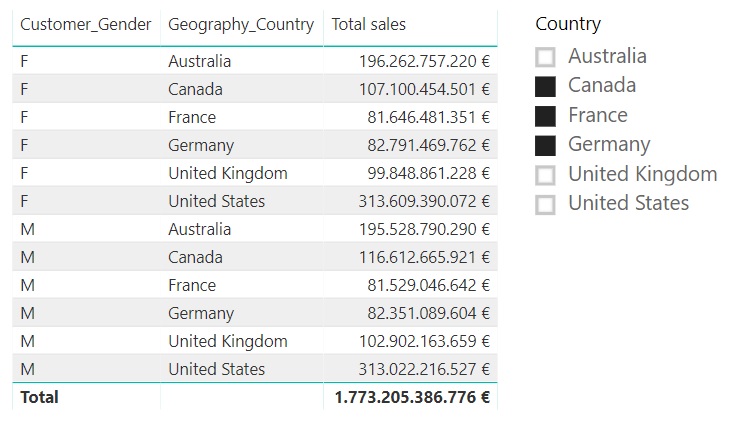
Comprobamos cómo, tal y como podía esperarse, la tabla no se ve afectada por el contexto de filtro.