La función value_counts() de Pandas nos permite calcular el número de apariciones de cada elemento único en una serie Pandas, devolviendo un listado de elementos únicos y el número de apariciones de cada uno. Pero podríamos estar interesados no en el número de veces que aparece cada elemento, sino en el número de elementos que aparecen N veces, para todos los valores posibles de N. Es decir, el uso de la función mencionada puede devolver como resultado que el valor 1 aparece, digamos, 2 veces, el valor 2 aparece una única vez, etc., pero si quisiéramos saber cuántos valores aparecen 1 vez (o N veces) tendríamos que utilizar la función value_counts() dos veces. Por ejemplo, consideremos el siguiente dataframe:

Si aplicamos la función value_counts() una vez, el resultado será el conjunto de elementos y el número de apariciones de cada uno:
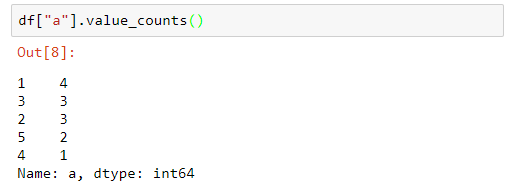
Vemos que el número 1 aparece 4 veces en el dataframe, el número 3 aparece 3 veces, etc. Si aplicamos la función value_counts a este resultado:
df["a"].value_counts().value_counts()
...nos devuelve el siguiente resultado:
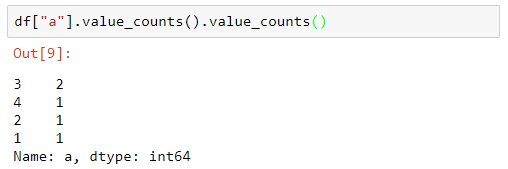
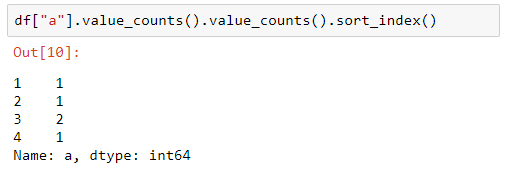
En este resultado vemos que la función se ha aplicado, tal y como esperábamos, al resultado anterior, devolviendo el número de elementos que aparecen N veces: así, hay 2 elementos que aparecen 3 veces, 1 elemento que aparece 4 veces, otro que aparece 2 veces y otro más que aparece 1 vez. Podemos ordenar este listado de la siguiente forma:
df["a"].value_counts().value_counts().sort_index()
...obteniendo el listado ordenado: