class sklearn.model_selection.KFold(n_splits=’warn’, shuffle=False, random_state=None)
La función sklearn.model_selection.KFold divide un conjunto de datos en k bloques. A continuación, considera uno de ellos como conjunto de validación y el resto como conjunto de entrenamiento, devolviendo las k combinaciones posibles (la primera combinación es la que considera el primer bloque como conjunto de validación y el resto como conjunto de entrenamiento, la segunda es la que considera el segundo bloque como conjunto de validación y el resto como conjunto de entrenamiento, etc.).
- n_splits: entero, valor por defecto = 3. Número de bloques en el que dividir el conjunto de datos.
- shuffle: boolean, opcional. Si toma el valor True, los datos se van a mezclar antes de generar los k bloques.
- random_state: entero o None, opcional, valor por defecto = None. Semilla a utilizar en el generador de números aleatorios cuando shuffle toma el valor True para la mezcla de los datos.
Supongamos que deseamos dividir un conjunto de 12 números (del 0 al 11, generados mediante la función range) en tres bloques, considerando uno de ellos como conjunto de validación y los otros dos como conjunto de entrenamiento, y generar los índices correspondientes para cada una de las combinaciones posibles:
from sklearn.model_selection import KFold
cv = KFold(n_splits = 3)
for train_indices, test_indices in cv.split(range(12)):
print(train_indices, test_indices)
El resultado devuelto es:

Si hacemos uso del argumento shuffle fijándolo al valor True:
from sklearn.model_selection import KFold
cv = KFold(n_splits = 3, shuffle = True)
for train_indices, test_indices in cv.split(range(12)):
print(train_indices, test_indices)
el resultado es:
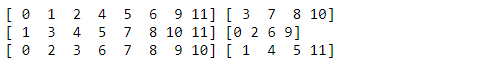
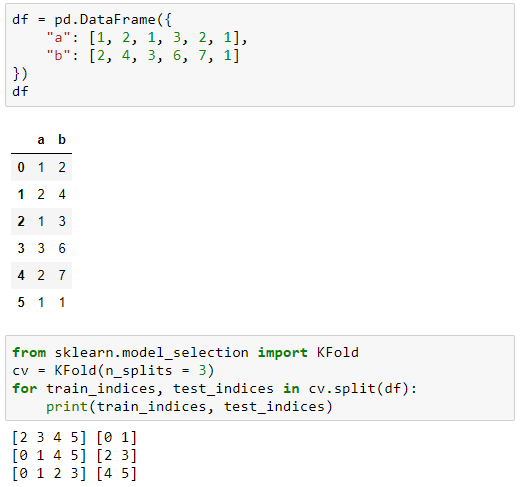
Si tenemos el siguiente dataframe:
df = pd.DataFrame({
"a": [1, 2, 1, 3, 2, 1],
"b": [2, 4, 3, 6, 7, 1]
})
..y queremos dividirlo en conjuntos de entrenamiento y validación a partir de 3 bloques de registros, el código a utilizar sería el siguiente:
from sklearn.model_selection import KFold
cv = KFold(n_splits = 3)
for train_indices, test_indices in cv.split(df):
print(train_indices, test_indices)